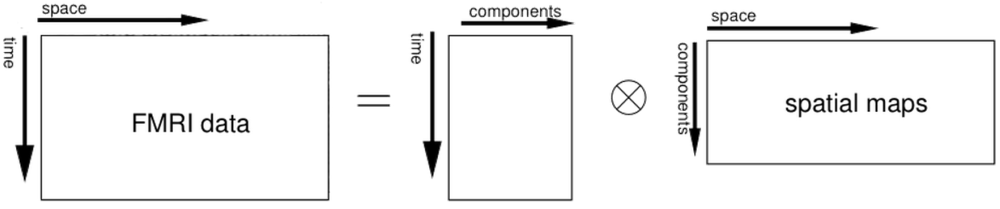
For our next step, we will be working with FSL example data - somewhat artificial data, true, and much better quality than anything you can ever expect from the likes of your data, which will only lead to toil, sweat, and the garret. Sufficient unto the day is the frustration thereof.
Open up the MELODIC gui either through the FSL gui, or through typing Melodic_gui from the command line. Most of the preprocessing steps can be kept as is. However, keep the following points in mind:
1. Double-check the TR. FSL will fill it in automatically from the header of the NIFTI file, but it isn't always reliable.
2. Spatial smoothing isn't required in ICA, but a small amount can help produce better-looking and more identifiable component maps. Somewhere on the order of the size of a voxel or two will usually suffice.
3. By default, MELODIC automatically estimates the number of components for you. However, if you have severe delusions and believe that you know how many components should be generated, you can turn off the "Automatic dimensionality estimation" option in the Stats tab, and enter the number of components you want.
4. The Threshold IC maps option is not the same thing as a p-value correction threshold. I'm not entirely clear on how it relates to the mixture modeling carried out by ICA, but my sense from reading the documentation and papers using ICA is that a higher threshold only keeps those voxels that have a higher probability of belonging to the true signal distribution, instead of the background noise distribution, and it comes down to a balance between false positives and false negatives. I don't have any clear guidelines about what threshold to use, but I've seen cutoffs used within the 0.8-0.9 range in papers.
5. I don't consider myself a snob, but I was using the bathroom at a friend's house recently, and I realized how uncomfortable that cheap, non-quilted toilet paper can be. It's like performing intimate hygiene with roofing materials.
6. Once you have your components, you can load them into FSLview and scroll through them with the "Volumes" button in the lower left corner. You can also load the Atlases from the Tools menu and double-click on it to get a semi-transparent highlight of where different cortical regions are. This can be useful when trying to determine whether certain components fall within network areas that you would expect them to.

However, it is a necessary step to see what ICA analysis ought to look like, as well as learning how to examine and identify components related to tasks and networks that you are interested in. Also - and possibly more important - you will learn to recognize sources of noise, such as components related to head motion and physiological artifacts.
First, go to the link http://fsl.fmrib.ox.ac.uk/fslcourse/ and scroll to the bottom for instructions on how to download the datasets. You can use either wget or curl. For this demonstration, we will be using datasets 2 and 6:
curl -# -O -C - http://fsl.fmrib.ox.ac.uk/fslcourse/fsl_course_data2.tar.gz
curl -# -O -C - http://fsl.fmrib.ox.ac.uk/fslcourse/fsl_course_data6.tar.gzOnce you have downloaded them, unzip them using gunzip, and then "tar -xf" on the resulting tar files. This will create a folder called fsl_course_data, which you should rename so that they do not conflict with each other. Within fsl_course_data2, navigate to the /melodic/av directory, where you will find a small functional dataset that was acquired while the participant was exposed to auditory stimuli and visual stimuli - which sounds much more scientific than saying, "The participant saw stuff and heard stuff."
Open up the MELODIC gui either through the FSL gui, or through typing Melodic_gui from the command line. Most of the preprocessing steps can be kept as is. However, keep the following points in mind:
1. Double-check the TR. FSL will fill it in automatically from the header of the NIFTI file, but it isn't always reliable.
2. Spatial smoothing isn't required in ICA, but a small amount can help produce better-looking and more identifiable component maps. Somewhere on the order of the size of a voxel or two will usually suffice.
3. By default, MELODIC automatically estimates the number of components for you. However, if you have severe delusions and believe that you know how many components should be generated, you can turn off the "Automatic dimensionality estimation" option in the Stats tab, and enter the number of components you want.
4. The Threshold IC maps option is not the same thing as a p-value correction threshold. I'm not entirely clear on how it relates to the mixture modeling carried out by ICA, but my sense from reading the documentation and papers using ICA is that a higher threshold only keeps those voxels that have a higher probability of belonging to the true signal distribution, instead of the background noise distribution, and it comes down to a balance between false positives and false negatives. I don't have any clear guidelines about what threshold to use, but I've seen cutoffs used within the 0.8-0.9 range in papers.
5. I don't consider myself a snob, but I was using the bathroom at a friend's house recently, and I realized how uncomfortable that cheap, non-quilted toilet paper can be. It's like performing intimate hygiene with roofing materials.
6. Once you have your components, you can load them into FSLview and scroll through them with the "Volumes" button in the lower left corner. You can also load the Atlases from the Tools menu and double-click on it to get a semi-transparent highlight of where different cortical regions are. This can be useful when trying to determine whether certain components fall within network areas that you would expect them to.
More details in the videos below, separately for the visual-auditory and resting-state datasets.